 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualThink-VLA: Visual Intermediate Reasoning for Effective and Low-Latency Vision-Language-Action Policies
May 28, 2026Recent work has begun to equip vision-language-action (VLA) policies with explicit intermediate reasoning. In embodied control, however, textual chain-of-thought is a poor fit: irrelevant or weakly textual information can interfere with action prediction, while autoregressive text decoding adds too much latency for real-time closed-loop execution. We present VISUALTHINK-VLA, a visual intermediate-reasoning framework for accurate, low-latency VLA policies. Our bootstrapping philosophy is to guide action with effective visual thinking: VISUALTHINK-VLA bootstraps action prediction through a compact visual-evidence interface that preserves spatial precision while avoiding decoding overhead. Besides, to further improve performance and efficiency, VISUALTHINK-VLA adopts a tailored selective routing mechanism to learn the visual evidence tokens, enabling low-latency inference while preserving high-capacity specialization. We also introduce VisualEvidence-Kit, a supervision-and-audit resource centered on a VisualEvidence-Agent that constructs a 754.7k VLA instructions VisualEvidence-Set for route supervision and counterfactual faithfulness tests. Across multiple benchmarks and real-robot evaluation, VISUALTHINK-VLA achieves the highest success rate on most benchmarks while reducing the multi-second latency of reasoning-augmented baselines to the sub-second regime. For example, on BridgeData V2, it reduces step latency from 8.377,s with ECoT to 0.367,s, achieving a 22.8 times speedup.
Hy-MT2: A Family of Fast, Efficient and Powerful Multilingual Translation Models in the Wild
May 21, 2026Hy-MT2 is a family of fast-thinking multilingual translation models designed for complex real-world scenarios. It includes three model sizes: 1.8B, 7B, and 30B-A3B (MoE), all of which support translation among 33 languages and effectively follow translation instructions in multiple languages. For on-device deployment, with AngelSlim 1.25-bit extreme quantization, the 1.8B model requires only 440 MB of storage and improves inference speed by 1.5x. Multi-dimensional evaluations show that Hy-MT2 delivers outstanding performance across general, real-world business, domain-specific, and instruction-following translation tasks. The 7B and 30B models outperform open-source models such as DeepSeek-V4-Pro and Kimi K2.6 in fast-thinking mode, while the lightweight 1.8B model also surpasses mainstream commercial APIs from providers such as Microsoft and Doubao overall.
Catching Every Ripple: Enhanced Anomaly Awareness via Dynamic Concept Adaptation
Apr 16, 2026Online anomaly detection (OAD) plays a pivotal role in real-time analytics and decision-making for evolving data streams. However, existing methods often rely on costly retraining and rigid decision boundaries, limiting their ability to adapt both effectively and efficiently to concept drift in dynamic environments. To address these challenges, we propose DyMETER, a dynamic concept adaptation framework for OAD that unifies on-the-fly parameter shifting and dynamic thresholding within a single online paradigm. DyMETER first learns a static detector on historical data to capture recurring central concepts, and then transitions to a dynamic mode to adapt to new concepts as drift occurs. Specifically, DyMETER employs a novel dynamic concept adaptation mechanism that leverages a hypernetwork to generate instance-aware parameter shifts for the static detector, thereby enabling efficient and effective adaptation without retraining or fine-tuning. To achieve robust and interpretable adaptation, DyMETER introduces a lightweight evolution controller to estimate instance-level concept uncertainty for adaptive updates. Further, DyMETER employs a dynamic threshold optimization module to adaptively recalibrates the decision boundary by maintaining a candidate window of uncertain samples, which ensures continuous alignment with evolving concepts. Extensive experiments demonstrate that DyMETER significantly outperforms existing OAD approaches across a wide spectrum of application scenarios.
IAD-Unify: A Region-Grounded Unified Model for Industrial Anomaly Segmentation, Understanding, and Generation
Apr 14, 2026Real-world industrial inspection requires not only localizing defects, but also explaining them in natural language and generating controlled defect edits. However, existing approaches fail to jointly support all three capabilities within a unified framework and evaluation protocol. We propose IAD-Unify, a dual-encoder unified framework in which a frozen DINOv2-based region expert supplies precise anomaly evidence to a shared Qwen3.5-4B vision-language backbone via lightweight token injection, jointly enabling anomaly segmentation, region-grounded understanding, and mask-guided generation. To enable unified evaluation, we further construct Anomaly-56K, a comprehensive unified multi-task IAD evaluation platform, spanning 59,916 images across 24 categories and 104 defect variants. Controlled ablations yield four findings: (i) region grounding is the decisive mechanism for understanding, removing it degrades location accuracy by >76 pp; (ii) predicted-region performance closely matches oracle, confirming deployment viability; (iii) region-grounded generation achieves the best full-image fidelity and masked-region perceptual quality; and (iv) pre-initialized joint training improves understanding at negligible generation cost (-0.16 dB). IAD-Unify further achieves strong performance on the MMAD benchmark, including categories unseen during training, demonstrating robust cross-category generalization.
DenoiseFlow: Uncertainty-Aware Denoising for Reliable LLM Agentic Workflows
Feb 28, 2026Autonomous agents are increasingly entrusted with complex, long-horizon tasks, ranging from mathematical reasoning to software generation. While agentic workflows facilitate these tasks by decomposing them into multi-step reasoning chains, reliability degrades significantly as the sequence lengthens. Specifically, minor interpretation errors in natural-language instructions tend to compound silently across steps. We term this failure mode accumulated semantic ambiguity. Existing approaches to mitigate this often lack runtime adaptivity, relying instead on static exploration budgets, reactive error recovery, or single-path execution that ignores uncertainty entirely. We formalize the multi-step reasoning process as a Noisy MDP and propose DenoiseFlow, a closed-loop framework that performs progressive denoising through three coordinated stages: (1)Sensing estimates per-step semantic uncertainty; (2)Regulating adaptively allocates computation by routing between fast single-path execution and parallel exploration based on estimated risk; and (3)Correcting performs targeted recovery via influence-based root-cause localization. Online self-calibration continuously aligns decision boundaries with verifier feedback, requiring no ground-truth labels. Experiments on six benchmarks spanning mathematical reasoning, code generation, and multi-hop QA show that DenoiseFlow achieves the highest accuracy on every benchmark (83.3% average, +1.3% over the strongest baseline) while reducing cost by 40--56% through adaptive branching. Detailed ablation studies further confirm framework-level's robustness and generality. Code is available at https://anonymous.4open.science/r/DenoiseFlow-21D3/.
Timely Parameter Updating in Over-the-Air Federated Learning
Dec 22, 2025Incorporating over-the-air computations (OAC) into the model training process of federated learning (FL) is an effective approach to alleviating the communication bottleneck in FL systems. Under OAC-FL, every client modulates its intermediate parameters, such as gradient, onto the same set of orthogonal waveforms and simultaneously transmits the radio signal to the edge server. By exploiting the superposition property of multiple-access channels, the edge server can obtain an automatically aggregated global gradient from the received signal. However, the limited number of orthogonal waveforms available in practical systems is fundamentally mismatched with the high dimensionality of modern deep learning models. To address this issue, we propose Freshness Freshness-mAgnItude awaRe top-k (FAIR-k), an algorithm that selects, in each communication round, the most impactful subset of gradients to be updated over the air. In essence, FAIR-k combines the complementary strengths of the Round-Robin and Top-k algorithms, striking a delicate balance between timeliness (freshness of parameter updates) and importance (gradient magnitude). Leveraging tools from Markov analysis, we characterize the distribution of parameter staleness under FAIR-k. Building on this, we establish the convergence rate of OAC-FL with FAIR-k, which discloses the joint effect of data heterogeneity, channel noise, and parameter staleness on the training efficiency. Notably, as opposed to conventional analyses that assume a universal Lipschitz constant across all the clients, our framework adopts a finer-grained model of the data heterogeneity. The analysis demonstrates that since FAIR-k promotes fresh (and fair) parameter updates, it not only accelerates convergence but also enhances communication efficiency by enabling an extended period of local training without significantly affecting overall training efficiency.
Rethinking Federated Learning Over the Air: The Blessing of Scaling Up
Aug 25, 2025Federated learning facilitates collaborative model training across multiple clients while preserving data privacy. However, its performance is often constrained by limited communication resources, particularly in systems supporting a large number of clients. To address this challenge, integrating over-the-air computations into the training process has emerged as a promising solution to alleviate communication bottlenecks. The system significantly increases the number of clients it can support in each communication round by transmitting intermediate parameters via analog signals rather than digital ones. This improvement, however, comes at the cost of channel-induced distortions, such as fading and noise, which affect the aggregated global parameters. To elucidate these effects, this paper develops a theoretical framework to analyze the performance of over-the-air federated learning in large-scale client scenarios. Our analysis reveals three key advantages of scaling up the number of participating clients: (1) Enhanced Privacy: The mutual information between a client's local gradient and the server's aggregated gradient diminishes, effectively reducing privacy leakage. (2) Mitigation of Channel Fading: The channel hardening effect eliminates the impact of small-scale fading in the noisy global gradient. (3) Improved Convergence: Reduced thermal noise and gradient estimation errors benefit the convergence rate. These findings solidify over-the-air model training as a viable approach for federated learning in networks with a large number of clients. The theoretical insights are further substantiated through extensive experimental evaluations.
GaRe: Relightable 3D Gaussian Splatting for Outdoor Scenes from Unconstrained Photo Collections
Jul 28, 2025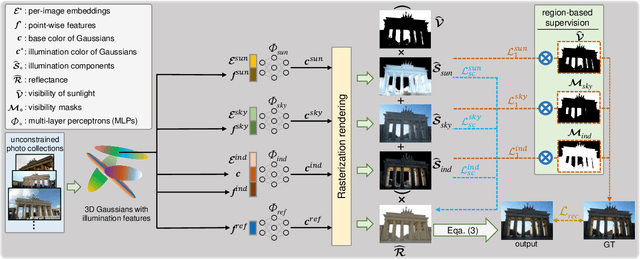

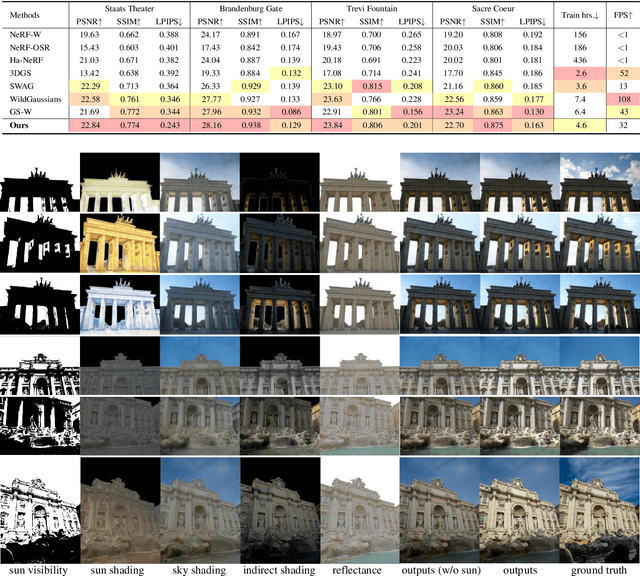

We propose a 3D Gaussian splatting-based framework for outdoor relighting that leverages intrinsic image decomposition to precisely integrate sunlight, sky radiance, and indirect lighting from unconstrained photo collections. Unlike prior methods that compress the per-image global illumination into a single latent vector, our approach enables simultaneously diverse shading manipulation and the generation of dynamic shadow effects. This is achieved through three key innovations: (1) a residual-based sun visibility extraction method to accurately separate direct sunlight effects, (2) a region-based supervision framework with a structural consistency loss for physically interpretable and coherent illumination decomposition, and (3) a ray-tracing-based technique for realistic shadow simulation. Extensive experiments demonstrate that our framework synthesizes novel views with competitive fidelity against state-of-the-art relighting solutions and produces more natural and multifaceted illumination and shadow effects.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Representation Learning with Mutual Influence of Modalities for Node Classification in Multi-Modal Heterogeneous Networks
May 12, 2025Nowadays, numerous online platforms can be described as multi-modal heterogeneous networks (MMHNs), such as Douban's movie networks and Amazon's product review networks. Accurately categorizing nodes within these networks is crucial for analyzing the corresponding entities, which requires effective representation learning on nodes. However, existing multi-modal fusion methods often adopt either early fusion strategies which may lose the unique characteristics of individual modalities, or late fusion approaches overlooking the cross-modal guidance in GNN-based information propagation. In this paper, we propose a novel model for node classification in MMHNs, named Heterogeneous Graph Neural Network with Inter-Modal Attention (HGNN-IMA). It learns node representations by capturing the mutual influence of multiple modalities during the information propagation process, within the framework of heterogeneous graph transformer. Specifically, a nested inter-modal attention mechanism is integrated into the inter-node attention to achieve adaptive multi-modal fusion, and modality alignment is also taken into account to encourage the propagation among nodes with consistent similarities across all modalities. Moreover, an attention loss is augmented to mitigate the impact of missing modalities. Extensive experiments validate the superiority of the model in the node classification task, providing an innovative view to handle multi-modal data, especially when accompanied with network structures.